Introduction
I went into the NeurIPS 2025 Google Code Golf Championship with zero prior code-golf experience—armed only with curiosity and a stubborn belief that a well-crafted agentic LLM loop could do the code golf for me. Instead of memorizing every byte-saving hack by hand, I built a lean, evolutionary agent and set it loose on the notorious ARC-AGI puzzle benchmark.
From the start, I was up against seasoned code-golf hobbyists and a leaderboard full of code golf veterans. For three months, my team and I tried everything: evolutionary solution databases, handcrafted code-golf templates, careful context engineering, and the occasional desperate manula crafted regex solution.
In the end, we finished 19th - but more importantly, we discovered what actually works (and what breaks) when you unleash an LLM-driven agent on competitive code golf.
This post is a practical field guide to that journey: how we built our agent, what finally moved the needle, where context rot kills you, and which human-injected templates turned into repeatable byte-savers. Whether you’re into LLMs, agents, or just love clever code, there’s something here for you—and maybe a template you’ll want to steal for your own golf game.
The Task!
At its core, this competition combines two objectives:
- Solve each ARC-AGI puzzle correctly; and
- Code-golf the working solution to the fewest bytes.
Understanding and solving an ARC-AGI task
ARC-AGI is a benchmark of grid-based abstraction-and-reasoning puzzles. Each task provides a handful of input→output examples on small colored grids. The goal is to infer a rule that generalizes to unseen inputs and to implement that rule in Python.
Here are some examples of the ARC-AGI tasks:
ARC-AGI Example 1

This is the Puzzle 1 of Arc AGI. Build a 9×9 grid arranged as a 3×3 grid of 3×3 blocks; For each 3×3 block at of the output, if the input cell , copy the entire 3×3 input into that block; otherwise fill that block with black.
ARC-AGI Example 2

This is the Puzzle 2 of Arc AGI. The patten of this specific task is to fill in every enclosed area of green point with yellow colour.
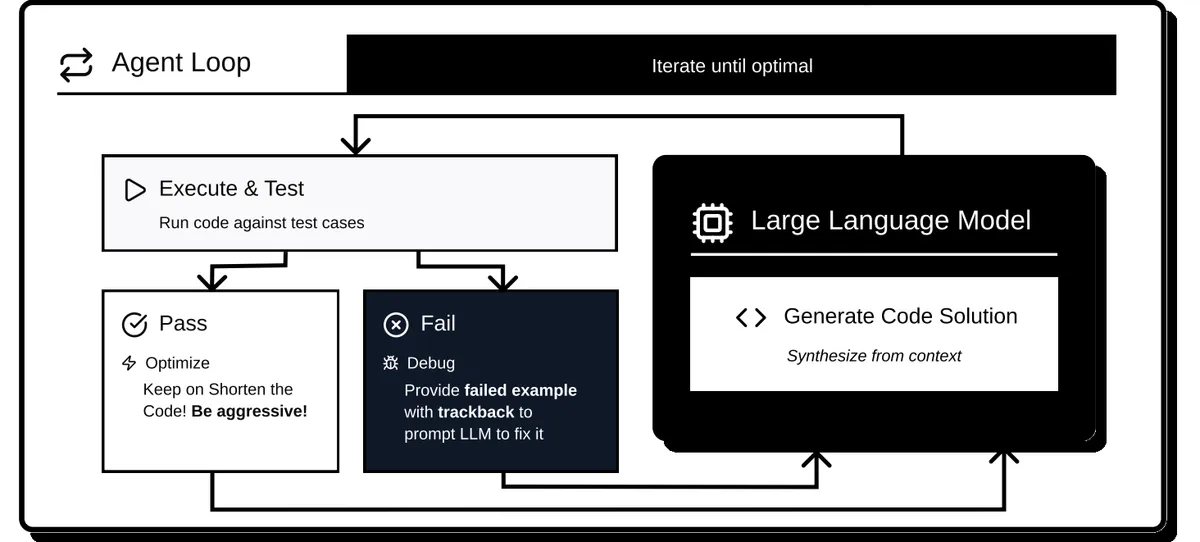
ARC-AGI Example 379
This is the Puzzle 379 of Arc AGI, The patten of this specific task is that we first need to extend each red dot toward the blue lines and then at which it intersect, we draw a blue square around the intersection.
Each puzzle is visualised as a coloured grid for readability; the underlying data are integer matrices with a fixed colour↔index palette (see mapping). This matrix form is what the Python code operates on.

For reference, the first input–output pair of Example 2 is:
At a glance, even humans need a moment to spot the rule in these examples. For LLMs, there are a few more factors that makes this even harder:
- Abstract, multi-step rules. Even humans pause to understand the pattern; ARC-AGI patterns are often abstract and compositional, causing LLMs to hallucinate heavily.
- Numeric form, spatial semantics. The inputs are matrices, but the underlying logic is more about spatial layout than arithmetic. LLMs, trained and heavily RL on mathematical problems, often misalign with or get confused by these topological tasks.
- High task diversity. With hundreds of distinct patterns, manual labeling or human-in-the-loop hints isn’t truely feasible. The LLM has to work it out alone.
To address these challenges, we experimented extensively with context engineering, crafting the right prompt context, balancing informativeness with brevity to avoid context rot. More details are in the context engineering section.
Code Golfing of working solution
Once correctness was locked in, the goal was to minimize byte length. Many standard code golf tricks help with this—like removing spaces, or using patterns such as:
for i in (1,2,3):# instead offor i in range(3):# to save 1 byteor
x>0<y# instead ofx>0 and y>0There are dozens of such tricks, but the real art of code golfing is escaping local minima. Beyond a point, saving a single character often requires a complete logic rewrite. In the final stages of the competition, trimming 1–2 bytes usually demanded a new approach.
For example, here’s our best solution for task 1:
p=lambda g:[[A&C for A in A for C in B]for A in g for B in g]While the public best solution (3 bytes shorter) is:
p=lambda*g:[[*g,min,p][2](r,s)for r in g[0]for s in g[-1]]Absolutely mind-blowing 🤯 (at least for me).
This gap led us to adopt two key tactics: (i) a living code golf idiom cookbook to teach byte-saving patterns, and (ii) a lightweight evolutionary database to seed the agent with diverse prior solutions, helping it escape local minima while preserving correctness.
My Agent
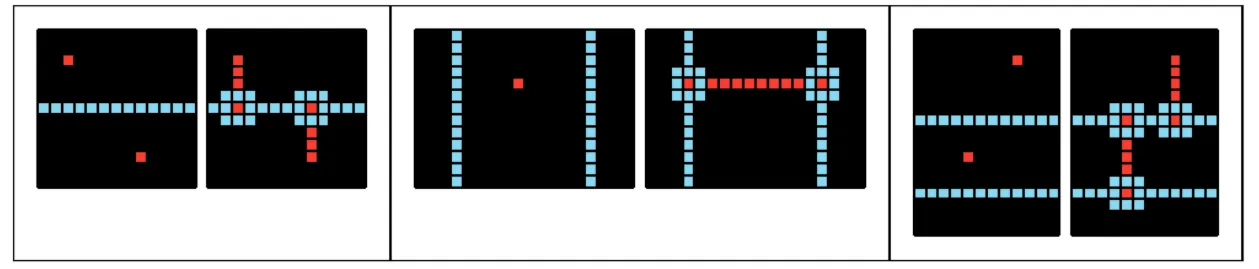
Given these challenges, the architecture below delivered reliable working solutions in the early stages, and consistent byte minimization in the later phases of the competition. At a high level, the system comprises three cooperating components (Fig. 1): an Evolutionary DB for retrieval and diversification; a Context Engineering stage that assembles the system prompt (role, task specification, ARC-GEN snippets, cross-task exemplars, golf idioms); and an Agent Loop that proposes code, runs tests, ingests failures, and retains the shortest correct program.
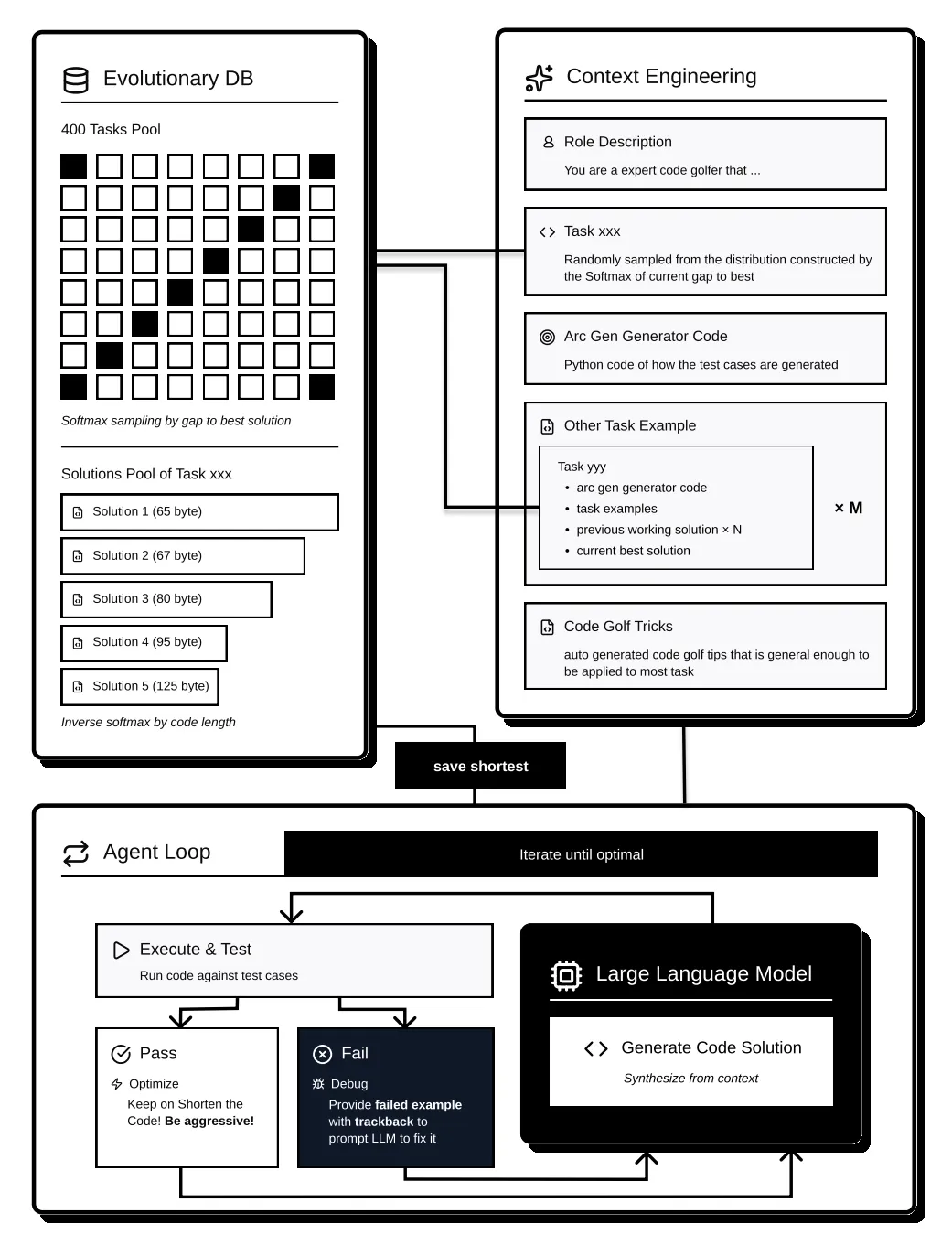 Figure 1: Architecture overview. The Evolutionary DB supplies tasks and prior solutions; Context Engineering assembles the prompt (role, task spec, ARC-GEN snippets, exemplars, golf idioms); the Agent Loop executes proposals, feeds back failures, and saves the shortest correct program.
Figure 1: Architecture overview. The Evolutionary DB supplies tasks and prior solutions; Context Engineering assembles the prompt (role, task spec, ARC-GEN snippets, exemplars, golf idioms); the Agent Loop executes proposals, feeds back failures, and saves the shortest correct program.
Components at a Glance
-
Evolutionary DB.
A pool of 400 tasks, each with its current best (lowest-byte) solution, plus a per-task set of correctness-verified prior LLM solutions that are longer than the best. These longer solutions are used for diversification and crossover. -
Context Engineering.
More a stage than a standalone component, this phase assembles the system prompt by experimenting with different sources of information to help the LLM better understand the task. The final prompt includes concise role instructions (as an expert code-golfer), the current task specification and ARC-GEN generator, a small selection of other tasks (with examples and best or near-best solutions) to induce transferable knowledge, and a golf idiom cookbook (safe, broadly applicable byte-saving patterns). -
Agent Loop (LLM + tools).
The LLM proposes code; a toolchain executes it against generator-defined tests, measures byte length, and returns tracebacks and failing I/O pairs on error. Passing proposals are compared to the best solution; the shortest correct solution is persisted and pushed back to the DB.
Agent Loop
This was the straightforward part: the system is essentially a program-synthesis loop tailored for ARC-AGI code golf. We designed this agentic loop to be as lean as possible, offloading most of the heavy lifting to Context Engineering and the Evolutionary DB. This was largely out of necessity, as we relied primarily on Gemini’s generous free tier (with occasional experiments on OpenRouter to test alternative models within a tight budget). To keep costs and latency down, we avoided heavy add-ons (like long-horizon planning, persistent memory, or code search) that would increase the number of LLM calls. The simple loop above gave us fast iteration, predictable costs, and let the LLM do the real work.
To build this lean agentic loop, we equipped it with a few essential tools:
- Extract code from LLM outputs (strip reasoning, capture the final Python block or code delimited by markers).
- Validate the snippet: ensure it defines a single entry point (
p(g)orp = lambda g: ...), uses only the Python standard library, and parses without syntax errors. - Run and score against task examples. On failure, return a concise traceback and the failing I/O pairs.
- Minify/normalize with
python-minifierfor easy byte wins (whitespace, imports, constant folding, safe name shortening), then measure the final byte count.
Thus the entire agent loop can thus be described as:
- Prompt the LLM with the system + user context to propose code.
- Extract → validate → minify. If invalid, feed back a short reason (syntax/import/entry-point).
- Execute tests.
- If pass: compare byte length to the incumbent; if shorter, persist as new best. Then asking it to continue shorten it.
- If fail: return the traceback + failing I/O pairs as the next user message.
- Iterate until the iteration budget is exhausted or no improvement for (K) rounds.
Here are some Validator guardrails that we checked when the LLM produced an answer:
- Enforce
def p(g): ...orp = lambda g: ...only; no top-level I/O. - Ban imports except safe stdlib used implicitly by the runner; no network/FS.
- Cap runtime per test; kill on timeouts; treat exceptions as failures.
- Normalise newlines and encoding before measuring
len(code.encode()).
Evolutionary DB
The Evolutionary DB is a lightweight index over tasks and solution variants, supporting both crossover and diversification. It stores per-task metadata and a history of correctness-verified working solution of each task (including longer variants), which seed structurally diverse rewrites.
Data model (per task):
best_bytes(our best),public_best_bytes(if known),solvedflagsolutions: correctness-verified programslast_updated, optionalpattern_signaturefor similarity search
Sampling for a new iteration:
-
Pick a focus task. This is the task the agent will attempt to solve or further shorten. Prefer tasks with room for improvement or those not yet solved. Sampling uses a softmax over the margin:
where controls exploitation vs. exploration.
-
Retrieve in-task priors. From the focus task’s archive, sample prior solutions with an inverse-length bias to favor concise patterns but maintain diversity:
-
Add cross-task exemplars. Select additional tasks to import transferable knowledge and help escape local minima. Early on, these were chosen at random; later, we switched to pattern-similarity retrieval via extracted pattern tags.
-
Crossover from priors. Include the best solution and a small set of diverse, correctness-verified working solutions from the selected exemplar tasks. These offer a record of how other tasks were golfed, allowing the model to transfer byte-saving motifs or refactor logic to the current task and synthesize a shorter, behavior-equivalent program.
-
Mutate. The LLM proposes a candidate; we run deterministic tests, capture failing I/O and tracebacks, and measure byte length post-normalization.
-
Update the DB. Any correct candidate is added to the archive; if it beats
best_bytes, it becomes the new incumbent.
This loop is easier to grasp with an example. Here’s how a sample prompt is constructed from the Evolutionary DB:
In this case, the DB selects Task 1 as the focus task, and retrieves several additional tasks (Tasks 239, 261, 397) as cross-task exemplars. The prompt begins by defining the role (“expert Python code-golfer”), then lists working solutions for each exemplar, and finally presents the focus task with a few of its prior working solutions. The prompt ends with a direct instruction to the LLM: synthesize a shorter program that still passes all tests—without copying existing code.
## RoleYou are an expert Python code golfer.14 collapsed lines
Your goal is to iteratively shorten working solutions while preserving their exact functionality.Focus only on minimizing **code size in bytes**, not efficiency or readability.
## Learning From Past TasksYou will be shown several solved tasks.Each includes:- One or more working solutions (sometimes with an improved, shorter version)
Study how the improved versions reduced code size.Use these patterns to guide your approach for the current task.
## Example Tasks
===Task 239:
You are tasked with producing the **shortest possible Python solution (in bytes)** that passes all the given test cases.
The current global best solution size is 99 bytes.43 collapsed lines
## Generator Function
This is the generator function used to create the puzzles that our solution function `p` is trying to solve for this specific task:
def generate(width=None, height=None, colors=None): """Returns input and output grids according to the given parameters.
Args: width: the width of the grid height: the height of the grid colors: a list of digits representing the colors to be used """ if width is None: width, height = common.randint(3, 4), common.randint(3, 4) colors, color_list = [0] * (width * height), common.random_colors(9) while True: left, right, top, bottom, idx = 0, width, 0, height, 0 while left < right and top < bottom: for r in range(top, bottom): for c in range(left, right): colors[r * width + c] = color_list[idx] didx = 0 if common.randint(0, 1): left, didx = left + 1, 1 if common.randint(0, 1): right, didx = right - 1, 1 if common.randint(0, 1): top, didx = top + 1, 1 if common.randint(0, 1): bottom, didx = bottom - 1, 1 idx += didx counts_to_colors = {colors.count(x): x for x in colors} if len(counts_to_colors) == idx: break
counts_to_colors = {colors.count(x): x for x in colors} counts = sorted(counts_to_colors.keys(), reverse=True) grid, output = common.grid(width, height), common.grid(len(counts), counts[0]) for r in range(height): for c in range(width): grid[r][c] = colors[r * width + c] for idx, count in enumerate(counts): for r in range(count): output[r][idx] = counts_to_colors[count] return {"input": grid, "output": output}
This generator creates the input/output pairs that define the puzzle pattern.
Here is version 1 (168 bytes):from collections import Counterdef p(j, R=range): c = Counter(sum(j, [])).most_common(9) return [[c[w][0] * (r < c[w][1]) for w in R(len(c))] for r in R(c[0][1])]
Here is version 2 (134 bytes):p=lambda g:[[v*(r<n)for n,v in C]for l in[sum(g,[])]for C in[sorted({(l.count(i),i)for i in{*l}})[::-1]]for r in range(C and C[0][0])]
Here is version 3 (111 bytes):def p(g):s=sum(g,[]);m=s.count;c=sorted({*s},key=m)[::-1];return[[i*(j<m(i))for i in c]for j in range(m(c[0]))]
The solutions show progressive improvement: from 168 bytes (version 1) to 111 bytes (version 3), saving 57 bytes total.You should learn from this progressive improvement to further shorten the code that I care about in the current task.There is still room for improvement compared to the global best solution: 12 bytes can potentially be saved (from 111 to 99 bytes).
===Task 397:
You are tasked with producing the **shortest possible Python solution (in bytes)** that passes all the given test cases.
The current global best solution size is 121 bytes.
45 collapsed lines
## Generator Function
This is the generator function used to create the puzzles that our solution function `p` is trying to solve for this specific task:
def generate(colors=None, brows=None, bcols=None, size=10): """Returns input and output grids according to the given parameters.
Args: colors: a list of digits representing the colors to be used brows: a list of vertical coordinates where the boxes should be placed bcols: a list of horizontal coordinates where the boxes should be placed size: the width and height of the (square) grid """ if colors is None: num_boxes = common.randint(2, 3) while True: bcols = sorted([common.randint(0, size - 2) for _ in range(num_boxes)]) wides = [2] * num_boxes if not common.overlaps_1d(bcols, wides): break while True: colors, brows = [], [] for _ in range(num_boxes): num_colors = common.randint(2, 4) color_list = common.random_colors(num_colors, exclude=[common.green()]) brows.append(common.randint(0, size - 2 - num_colors)) colors.extend([common.choice(color_list) for _ in range(4)]) touching = False for i in range(num_boxes - 1): if abs(brows[i] - brows[i + 1]) < 2: touching = True if touching: continue break
grid, output = common.grids(size, size) for idx in range(len(colors) // 4): for r in range(2): for c in range(2): grid[brows[idx] + r][bcols[idx] + c] = colors[idx * 4 + r * 2 + c] output[brows[idx] + r][bcols[idx] + c] = colors[idx * 4 + r * 2 + c] shadow = len(set(colors[idx * 4 : (idx + 1) * 4])) for r in range(shadow): for c in range(2): output[brows[idx] + r + 2][bcols[idx] + c] = common.green() return {"input": grid, "output": output}
This generator creates the input/output pairs that define the puzzle pattern.
Here is version 1 (208 bytes):p=lambda g,R=range:(Z:=[(B,A,len({*f}))for B in R(9)for A in R(9)if all(f:=(g[B][A],g[B][A+1],g[B+1][A],g[B+1][A+1]))])and[g[C].__setitem__(slice(A,A+2),[3,3])for B,A,H in Z for I in R(H)if(C:=B+2+I)<10]and g
Here is version 2 (158 bytes):def p(g): R=range for i in R(63): r=6-i//9;c=i%9 f=g[r][c:c+2]+g[r+1][c:c+2] h=len({*f})*all(f) for j in R(h):g[r+2+j][c:c+2]=[3,3] return g
Here is version 3 (139 bytes):def p(i): for t in range(63): a=6-t//9;t%=9;r=i[a][t:t+2]+i[a+1][t:t+2] for o in i[a+2:][:len({*r})*all(r)]:o[t:t+2]=3,3 return i
The solutions show progressive improvement: from 208 bytes (version 1) to 139 bytes (version 3), saving 69 bytes total.You should learn from this progressive improvement to further shorten the code that I care about in the current task. There is still room for improvement compared to the global best solution: 18 bytes can potentially be saved (from 139 to 121 bytes).
===Task 261:
You are tasked with producing the **shortest possible Python solution (in bytes)** that passes all the given test cases.
The current global best solution size is 47 bytes.36 collapsed lines
## Generator Function
This is the generator function used to create the puzzles that our solution function `p` is trying to solve for this specific task:
def generate(size=None, rows=None, cols=None): """Returns input and output grids according to the given parameters.
Args: size: the width and height of the (square) grid rows: a list of vertical coordinates where pixels should be placed cols: a list of horizontal coordinates where pixels should be placed """ if size is None: size = common.randint(3, 7) width = common.randint(size // 2, (size + 1) // 2) height = common.randint(size // 2, (size + 1) // 2) row = common.randint(0, size - height - 1) col = common.randint(0, size - width) while True: pixels = common.random_pixels(width, height, 0.5) if not pixels: continue rows, cols = zip(*pixels) rows, cols = [r + row for r in rows], [c + col for c in cols] break
grid, output = common.grids(size, size) for r, c in zip(rows, cols): grid[r][c] = common.cyan() output[r + 1][c] = common.red() return {"input": grid, "output": output}
This generator creates the input/output pairs that define the puzzle pattern.
Here is version 1 (152 bytes):def p(m): a=[[0 if v==8 else v for v in r]for r in m] [a[i+1].__setitem__(j,2)for i,r in enumerate(m[:-1])for j,v in enumerate(r)if v==8] return a
Here is version 2 (57 bytes):p=lambda g:[*map(lambda r:[v>>2 for v in r],[g.pop()]+g)]
Here is version 3 (47 bytes):p=lambda g:[[v%3for v in r]for r in[g.pop()]+g]
The solutions show progressive improvement: from 152 bytes (version 1) to 47 bytes (version 3), saving 105 bytes total.You should learn from this progressive improvement to further shorten the code that I care about in the current task.
===
## Current TaskYou are now given **Task 1** with test cases and a working solution.Your objective: shorten the solution toward or beyond the global best size, while ensuring it still passes all test cases.
===Task 1:
You are tasked with producing the **shortest possible Python solution (in bytes)** that passes all the given test cases.
The current global best solution size is 61 bytes.66 collapsed lines
## Generator Function
This is the generator function used to create the puzzles that our solution function `p` is trying to solve for this specific task:
def generate(rows=None, cols=None, color=None, size=3): """Returns input and output grids according to the given parameters.
Args: rows: a list of vertical coordinates where pixels should be placed cols: a list of horizontal coordinates where pixels should be placed color: a digit representing a color to be used size: the width and height of the (square) grid """ if rows is None: pixels = common.sample(common.all_pixels(size, size), common.randint(2, 8)) rows, cols = zip(*pixels) color = common.random_color()
grid, output = common.grid(size, size), common.grid(size * size, size * size) for r, c in zip(rows, cols): grid[r][c] = color for rr, cc in zip(rows, cols): output[rr * size + r][cc * size + c] = color return {"input": grid, "output": output}
This generator creates the input/output pairs that define the puzzle pattern.
## Test Cases
**Example 1:**Input:[[0, 1, 1], [0, 0, 0], [0, 1, 1]]Output:[[0, 0, 0, 0, 1, 1, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 1, 1]]
**Example 2:**Input:[[0, 3, 3], [3, 3, 0], [0, 3, 3]]Output:[[0, 0, 0, 0, 3, 3, 0, 3, 3], [0, 0, 0, 3, 3, 0, 3, 3, 0], [0, 0, 0, 0, 3, 3, 0, 3, 3], [0, 3, 3, 0, 3, 3, 0, 0, 0], [3, 3, 0, 3, 3, 0, 0, 0, 0], [0, 3, 3, 0, 3, 3, 0, 0, 0], [0, 0, 0, 0, 3, 3, 0, 3, 3], [0, 0, 0, 3, 3, 0, 3, 3, 0], [0, 0, 0, 0, 3, 3, 0, 3, 3]]
**Example 3:**Input:[[0, 6, 0], [0, 0, 0], [0, 6, 6]]Output:[[0, 0, 0, 0, 6, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 6, 6, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 6, 0, 0, 6, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 6, 6, 0, 6, 6]]
**Example 4:**Input:[[0, 0, 1], [0, 0, 1], [1, 0, 0]]Output:[[0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0]]
**Example 5:**Input:[[0, 0, 5], [5, 0, 5], [0, 0, 0]]Output:[[0, 0, 0, 0, 0, 0, 0, 0, 5], [0, 0, 0, 0, 0, 0, 5, 0, 5], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 5, 0, 0, 0, 0, 0, 5], [5, 0, 5, 0, 0, 0, 5, 0, 5], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0]]
The test cases are generated by the `generate` function. You should make sure that the solution still passes all the test cases.
Here is the 1th working solution (98 bytes):
p=lambda g:[[g[a][b]&g[c][d]for d in range(3)for b in range(3)]for c in range(3)for a in range(3)]
Here is the 2th working solution (84 bytes):
p=lambda g:[[g[a//3][b//3]&g[a%3][b%3]for b in(0,1,2,3,4,5,6,7,8)]for a in range(9)]
This is the current best solution (61 bytes):
p=lambda g:[[A&C for A in A for C in B]for A in g for B in g]
This current best solution have 61 bytes, and the global best possible score is 58 bytes.We want to improve the current solution to the global best possible score while keeping the same functionality.
You should not repeat the best solution code, and you should not repeat the working solution code. You should use all the insight and understanding of the working solution and the best solution to further shorten the code, and provide the shortened version of the code.Context Engineering
This was where we spent most of our time: figuring out what information helps the agent reason effectively, and what causes the LLM to suffer from context rot or distraction.
We divided this into two key parts:
- Prompt Construction for Solving ARC-AGI — information that helps the LLM produce a working solution to an ARC-AGI task.
- Prompt Construction for Code Golfing — information that helps the LLM shorten or golf an already working solution.
Prompt Construction for Solving ARC-AGI
When I joined the competition, several existing community resources were already invaluable for bootstrapping first working solutions:
-
arc-dsl — A Domain-Specific Language for ARC-AGI tasks, with a Python DSL file that defines composable primitives for common visual and logical transformations. While not comprehensive, these building blocks can express a large portion of ARC-AGI tasks. There’s also a solver module showing how to assemble complete solutions with the DSL.
-
ARC-GEN — This repo contains the generator code for the ARC-AGI competition dataset. Each generator defines a family of puzzles with shared transformations. Although it doesn’t always expose the high-level pattern directly, it provides crucial signals to help the model infer the underlying rules and constraints.
To ground the model further, we included a few raw input→output pairs as plain matrices, e.g.:
**Example 1:**Input:[[0, 1, 1], [0, 0, 0], [0, 1, 1]]Output:[[0, 0, 0, 0, 1, 1, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 1, 1]]First-pass system prompt
With these components in place, here’s the first version of the system prompt I used:
- System role (expert Python code-golfer for ARC-AGI)
- Exemplar tasks
- ARC-GEN generator snippet
- arc-dsl solution
- Working solutions from the evolutionary database
- Focus task
- ARC-GEN generator snippet
- arc-dsl solution
- Task examples (input→output pairs)
- Output rules enforcing a short, single-function, working program for the focus task
This prompt solved about half the tasks without manual coding, even with a fast, non-flagship model (gemini-2.5-flash). However, progress plateaued. We traced this to a mismatch between arc-dsl assumptions and the ARC-GEN task distributions:
- Generator drift / artefacts: The competition included many extra examples per task generated from ARC-GEN, some deviating subtly from the “canonical” pattern that is described in the original arc-agi task.
- DSL shortcuts: Some arc-dsl solutions solved the original training/test grids via clever shortcuts, but didn’t generalize to the broader examples.
The upshot: arc-dsl sometimes confused the model on certain tasks. Our fix was simple but effective, we removed arc-dsl code from the prompt, keeping only ARC-GEN snippets.
After this pruning, the agentic loop resumed and reached ~360 solved tasks. For the remainder, I wrote manual solutions or adapted vetted public ones into the codebase.
Prompt Construction for Code Golfing
This is where we assembled a compact, high-leverage set of code-golf idioms.
Sourcing the idioms
I started by asking the model for generic Python golf tips. These were helpful, but shallow. Next, I searched community resources. Most code-golf sites only show solution lengths, not code, so transfer is limited. Eventually, I found an archived competition site: https://steffan153.github.io/wg-sol/. It has fewer than 50 problems; most aren’t matrix-heavy, but a few transfer well to ARC-AGI. The key: submissions are visible and ranked by length, so you can track the incremental byte-saving tricks. I used ChatGPT agent mode to crawl the archive and distill recurring patterns into prompt-ready snippets.
The Evolutionary DB as a teacher
Beyond the codebook, the Evolutionary DB turned out to be the best teacher for code golf. When a breakthrough happens—like a logic refactor that shaves bytes but preserves behavior—subsequent runs can retrieve that variant, and the model will often transfer the same motif to a different task with a similar pattern. In some cases, the transfer is almost direct. For example, Task 246 and Task 335 share the same pattern, differing only in numbers/colors:
ARC-AGI Example 246

Puzzle 246 of ARC-AGI: Extend the red dot rightward and the green dot upward with a blue trace; stop when they meet.
ARC-AGI Example 335
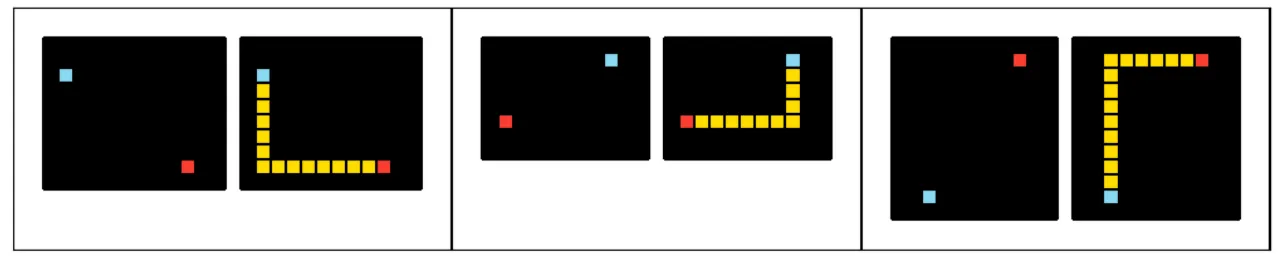
Puzzle 335 of ARC-AGI: Extend the red dot leftward and the blue dot downward with a yellow trace; stop when they meet.
So they are basically the same pattern.
Thanks to the Evolutionary DB-as-teacher approach, a breakthrough on one propagates to the other, so the final solutions are almost identical:
def p(g): D,E=sum(g,[]).index,divmod;F,C,A,B=E(D(3),(G:=len(g[0])))+E(D(2),G) while B-C:B+=B<C or-1;g[A][B]=8 while A-F:g[A][C]=8;A+=A<F or-1 return gand
def p(g): D,E=sum(g,[]).index,divmod;F,C,A,B=E(D(8),G:=len(g[0]))+E(D(2),G) while B-C:B+=B<C or-1;g[A][B]=4 while A-F:g[A][C]=4;A+=A<F or-1 return gThis is an extreme example, but we frequently saw related patterns across tasks. That’s exactly where the Evolutionary DB shines in our agent.
Fighting context rot
We learned the hard way that too many input→output pairs, exemplars, and prior solutions can make the model drift. Early on, we used about 10 I/O pairs, 8 exemplars, and ~10 prior solutions per prompt—often blowing the context window. We pruned aggressively:
- I/O pairs: 10 → 5
- Cross-task exemplars: 8 → 3
- Prior solutions: 10 → 3 (and we shortened the long early arc-dsl solutions, which were often hundreds of lines)
Why fewer I/O pairs?
- Grids can be large (e.g., 28×28), and matrices are extremely token-inefficient: each digit, bracket, and comma is a token, so token count scales quickly.
Why fewer prior solutions?
- Early “working” solutions inherited from arc-dsl were often verbose scaffolding, with really long but working solution. Including too many consumed context and distracted the model.
Why fewer exemplars?
- More random exemplars increased the odds of hitting a useful match (tasks with similar patterns), but also injected noise.
- Instead, we added pattern tags per task (e.g., flood-fill, flip, extend rays, copy block), derived from the DSL’s modular sub-patterns. When sampling, we only retrieve pattern-similar tasks—cutting exemplars from 8 to 3 without losing relevance.
When scaling models stopped helping
About halfway through the competition (~1 month left, leaderboard ≈ 0.940xxx), we hit a ceiling. We tried switching to larger and newer models (qwen3-coder, kimi-k2, deepseek-R1, gemini-2.5-flash-lite → gemini-2.5-flash → gemini-2.5-pro) and expanded the “thinking budget” (12k → 32,768 tokens). But—no further shortenings.
At this point, neither prompt design nor retrieval was the bottleneck. The remaining tasks required fundamentally different logic—not just more “thinking.” I considered the agent to be saturated, merged into a team, and started manual coding to finish the tail.
Human-Injected Template Knowledge
While manual coding, we noticed recurring task families—for example, problems where the “natural” solution is DFS, BFS, flood-fill, or another grid search. From a code-golf perspective, these are painful: queues, boundary checks, four-direction neighbor sets, multi-line loops—the byte cost adds up fast. The good news is that many can be reframed in a much simpler way that compresses extremely well.
Here’s a detailed example showing how we (i) manually improved a working solution, (ii) abstracted that improvement into a template, and (iii) injected the template back into the agent so it could be reused elsewhere. This is a step outside the main agent loop, but the template is the key takeaway that powers future automated gains. We discovered several such templates throughout the competition, but here I’ll use Example 2 to demonstrate the process—this was my first manual breakthrough.
Example task (ARC-AGI Example 2):
The task: fill any zero (black) that is enclosed by 3s (green border) with 4 (yellow). Zeros that can “see” the border (via a path of zeros) should stay zero; all others turn to 4.
A natural solution: BFS/flood-fill. Here’s a baseline solution:
def p(g): R=range;l=len(g);q=[] for i in R(l):q+=[(i,0),(i,l-1),(0,i),(l-1,i)] while q: i,j=q.pop() if -1<i<l and -1<j<l and not g[i][j]: g[i][j]=1;q+=[(i+x,j+y)for x,y in((1,0),(-1,0),(0,1),(0,-1))] for i in R(l): for j in R(l): if not g[i][j]:g[i][j]=4 elif g[i][j]==1:g[i][j]=0 return gWhat this 320-byte baseline does: It seeds a queue with border coordinates and flood-fills through zeros to mark everything reachable from the border. On the final scan:
- Zeros never reached by the flood-fill are enclosed → set to
4 - Zeros visited by the flood-fill are temporarily marked → restore to
0
This is robust but costly (in terms of byte): explicit queue, boundaries, four neighbors, multi-line loops.
The code-golf perspective: “rotate and erode”
Instead of growing a region from the border, we prefill and then erode exposure:
- Prefill: Assume all zeros are enclosed and set them to
4. - Erode: Any
4touching the outside via a chain of zeros is reverted to0. We implement this by checking just the left neighbor and rotating the grid 90° each pass:- Pass 1: If the left neighbor is
0, the current4becomes0(exposed from the west). - Rotate 90°, repeat (north); again (east); again (south).
- After four rotations, all directions are covered. Only truly enclosed cells remain
4.
- Pass 1: If the left neighbor is
This collapses BFS into a terse, single-expression update + rotate loop, which golfs extremely well.
Our 104-byte solution for Example 2 (“rotate and scan”):
p=lambda q,a=95:q*-a or p([*zip(*[map(lambda r,H:H*(H^4|r>0)or a//95*4,[0,*x],x)for x in q[::-1]])],a-1)How the one-liner works:
ais an iteration budget (multiple of 4 to fully sweep all directions, returning to original orientation).- First pass: (
a//95 == 1) prefill zeros to4. - Later passes: For each cell, if
A==4and left neighborL==0, setA=0(exposed). q[::-1]+zip(*)rotates the grid 90°, so a single left-neighbor rule is applied in all directions over four passes.
From one-off insight to reusable template
We saved 200 bytes by reframing the problem. But: simply dropping this solution into the Evolutionary DB wasn’t enough, as such “logic leaps” can confuse the LLM when reused cold. So we started to extract the pattern as a template, to be injected into the prompt when a similar task appears.
The reusable “rotate-and-update” template: Generalise the idea as a rotate-and-update loop: write a per-cell update that looks only “left”; rotation covers all directions. Still golf-friendly—no queues, single expression.
# n = iteration counter (keep n a multiple of 4 so orientation resets)p=lambda o,n=95:-n*o or p( [*zip(*( ((A # <— replace with your per-cell update for L,A in zip((0,*r),r)) for r in o[::-1] ))],-~n)Examples for the update line:
(A+(L==k)*(A<k))# bump A if left is k(A,L)[cond]# choose L over A if condition met(x(A),A)[flag]# one-off transform
For Example 2, the per-cell update:
- First pass: zeros become
4 - Subsequent passes: if
A==4andL==0, setA=0(erode)
This template typically saves 50–100 bytes per program for these task families. Stacking such templates produces large aggregate gains.
Why this matters for the agent: The point isn’t just manual golfing, it’s to harvest a template. Once crystallised, we inject the template into the agent’s system prompt. The Evolutionary DB then surfaces similar tasks, and the agent can reuse the motif automatically—turning a one-off breakthrough into a repeatable byte saver.
What didn’t work (and where we hand-golfed)
There was an ongoing discussion during the competition about what LLMs struggle with. Our experience mostly matched it:
- Regex never stuck. Even with templates and human-solved examples that used regex, the agent rarely synthesized a correct, byte-minimal regex. When regex was useful, we almost always had to hand-write it.
- Bitwise ops worked perfectly. When presented with multiple working solutions, the LLM reliably understood the logic and exploited bitwise operations wherever they applied.
- Recursion was fine—with a template. Once we built a solid template for recursion-related problems, the agent could use them reliably.
- Large logic pivots needed scaffolding. Whenever a breakthrough required a full reframing (like rotate-and-erode), the agent struggled, unless we packaged it as a reusable template and surfaced it via the Evolutionary DB.
Conclusion
That’s my slice of the system: a lean agentic loop, held together by Context Engineering and an Evolutionary DB, plus a handful of human-injected templates that traveled well. In parallel, my teammates explored other directions—compressing functions with zlib, AST-aware normalization to remove redundant characters, running smaller models augmented with better golf idioms, and even golfing with Claude Code. It was three months of steady grind, but deeply rewarding—and I learned a lot.
If you spot issues or want to build on this, I’ll publish the GitHub repo here once I finish tidying it up.
How to cite
BibTeX
@misc{mao2025golfingarcagi, title = {Golfing ARC-AGI with a Lean Agentic Loop}, author = {Mao, Yuchen}, year = {2025}, month = {nov}, howpublished = {\url{https://yuchen-mao.vercel.app/blog/google-code-golf}}, note = {Blog post}}Thanks for reading!